
![]()
Adsum IoT Coder – for nRF
An open-source IoT coding agent that cracks the complex firmware bugs general agents struggle with — in less context, fewer tokens, and less time. Backed by live device-log capture, curated SDK knowledge, and an open benchmark on real nRF hardware.
Shipping today: nRF52 / nRF53 / nRF54 · BLE · nRF Connect SDK (Zephyr). On the roadmap: Wi-Fi · LTE-M · Matter · ESP-IDF · additional RTOS support.
Open source under Apache 2.0.


![]()
Watch the demo → · Install → · Benchmark → · Architecture → · Roadmap →

What’s New v0.1.5
![]() A full UI redesign — rebuilt around how you actually start. Early users told us the hardest part wasn’t the agent, it was the cold start. So we rebuilt the entire first-run experience: see the tool work before any setup, land on something useful immediately, and always have a clear next step.
A full UI redesign — rebuilt around how you actually start. Early users told us the hardest part wasn’t the agent, it was the cold start. So we rebuilt the entire first-run experience: see the tool work before any setup, land on something useful immediately, and always have a clear next step.
![]() See it debug a real bug — in 30 seconds, before you set anything up. A new first-run demo debugs a real BLE bug on firmware bundled with the extension. No board, no API key, no project of your own required — watch the capture-analyze-fix loop on a genuine failure, then run it on your own firmware.
See it debug a real bug — in 30 seconds, before you set anything up. A new first-run demo debugs a real BLE bug on firmware bundled with the extension. No board, no API key, no project of your own required — watch the capture-analyze-fix loop on a genuine failure, then run it on your own firmware.
![]() Zero-config first run. Install and you land straight on something that works — no provider-selection screen standing between you and the agent. The free tier is already on; bring your own key whenever you’re ready.
Zero-config first run. Install and you land straight on something that works — no provider-selection screen standing between you and the agent. The free tier is already on; bring your own key whenever you’re ready.
![]() A home screen that guides the next step. With a project open, the agent reads what it is and offers the right moves as one-click workflow cards — Build, flash & debug, Add a feature, Test & validate — with SDK migration and board bring-up on the way. After any task finishes, it suggests where to go next instead of leaving you at a blank prompt; with no project open, it points you to start a prototype or open your nRF project.
A home screen that guides the next step. With a project open, the agent reads what it is and offers the right moves as one-click workflow cards — Build, flash & debug, Add a feature, Test & validate — with SDK migration and board bring-up on the way. After any task finishes, it suggests where to go next instead of leaving you at a blank prompt; with no project open, it points you to start a prototype or open your nRF project.
![]() Instant key switchover. Add your own provider mid-session — the running task continues, no restart.
Instant key switchover. Add your own provider mid-session — the running task continues, no restart.
Full history in the changelog.
Contents
- Why Adsum IoT Coder exists
- Architecture — Dynamic Knowledge & Tool-Skill Loading
- Benchmark — IoT-FirmwareDebugBench v0.1
- Getting Started
- Roadmap
- Limitations
- Citing this work
- About
- Contributing
- Privacy & Security
- Troubleshooting
Why Adsum IoT Coder exists
Adsum IoT Coder specialises in IoT communication firmware — wireless protocol stacks (Bluetooth Low Energy / BLE today; Wi-Fi, Thread, Matter, LTE-M on the roadmap) and the related power-budget concerns that come with them. This is not a general embedded-systems agent: it isn’t trying to help you write a motor controller or a DSP pipeline. It is built for the specific class of bugs that show up in connected devices.
That class of bug fails general coding agents for structural reasons — not model capability. The problems live outside the source code:
- A
settings_load()call missing afterbt_enable()compiles fine, connects fine, and silently breaks GATT notifications after the first reconnect. - An advertising filter with an empty accept list makes the device scannable but impossible to connect to — with zero errors in the log.
- A Central/Peripheral connection-parameter mismatch only surfaces when you correlate timestamps across two separate log streams.
- A BLE peripheral that pairs cleanly under test but drops bond state every cold boot because
CONFIG_BT_SETTINGSis set without flash storage backing it. - An advertising interval that fits the radio spec but blows the battery budget on the first field deployment.
None of these are visible in the source code; all of them are common in real BLE/IoT projects. Diagnosing them requires capabilities general coding agents don’t have.
What an IoT-communication debugging agent needs
Four capability pillars — split between what ships today and what’s on the roadmap:
| Pillar | Today (shipping) | Roadmap |
|---|---|---|
| Native SDK integration General coding agents read source; they don’t drive the NCS toolchain. |
nRF Connect SDK v3.2.1, Zephyr build/flash, board-aware project assessment | Older NCS LTS versions, ESP-IDF |
| Hardware-in-the-loop instrumentation Most IoT failures only show in physical signals from the chip — not files in your repo. |
Live RTT/UART log capture, J-Link control, multi-device simultaneous capture and correlation | BLE sniffer (Wireshark / nRF Sniffer), PPK II power profiling, spectrum analysis |
| Expert-reviewed IoT comms knowledge The “I’ve seen this failure before” pattern recognition that takes senior engineers years to build, curated as modules. |
BLE protocol stack, NCS/Zephyr internals (Kconfig, settings/bonding, BLE lifecycle traps), nRF52/53/54 board specifics, curated BLE failure-mode library | Wi-Fi, Thread, Matter, LTE-M, DECT NR+ protocol modules; power-budget analysis; low-power optimization; protocol-correctness review |
| Tool-use skills for IoT debugging Knowing when to flash vs. recheck logs vs. spin up another tool is itself expertise. |
log-analyzer, log-generator, debug-loop workflows; discrete capture-logs / analyze-logs / build / flash actions — each loaded only when the task calls for it |
Additional workflows as new protocols and HITL tooling land |
Architecture — Dynamic Knowledge & Tool-Skill Loading
From proof of concept to platform
Adsum IoT Coder is an AI coding agent built on the open-source Cline foundation, with IoT-specific knowledge modules and tool-use skills layered on top. Two months ago we shipped the first version — nRF AI Debugger — as a proof of concept to test whether purpose-built AI tooling could meaningfully outperform general coding agents on embedded IoT firmware. The proof of concept got real traction, but v1’s architecture loaded its full domain expertise into every session — a static bundle that worked but couldn’t grow. Adding nRF9x or nRF7x support meant expanding the bundle. Adding ESP, Thread, or Matter meant the same. The architecture sat on a cliff edge.
Modules loaded on demand
This release inverts that. Domain knowledge and tool-use skills are structured as a framework of discrete, composable modules — each scoped to a specific chip family, protocol stack, or debug capability. At session start, the agent assesses what the project is and what the task requires, then fetches the relevant modules on demand.
User task ──► Agent assesses project ──► Loads scoped modules ──► Executes
(chip family, (only what's needed (Build → Flash →
protocol stack, from iot-knowledge/) Capture → Analyze
debug category) → Fix, looped)
The module tree on disk:
iot-knowledge/
├── rules/ # Platform-agnostic agent constraints
│ ├── core.md # Universal embedded development rules
│ ├── tool-routing.md # When to use nRF terminal vs standard shell
│ └── device-identity.md # Never guess device roles from board type
├── platforms/nrf/ # Adsum IoT Coder – for nRF (shipping)
│ ├── PLATFORM.md # Master index — what to load and when
│ ├── boards/ # Per-SoC: nRF52840, nRF52832, nRF5340
│ ├── sdks/ncs/ # NCS project structure, Kconfig, BLE stack
│ │ ├── protocols/BLE.md # BLE-specific modules
│ │ └── SDK.md # NCS-specific modules
│ ├── workflows/ # Entry-point sequences (start here)
│ │ ├── log-analyzer.md # Capture → Analyze → Report
│ │ ├── log-generator.md # Instrument firmware with LOG_* macros
│ │ └── debug-loop.md # Build → Flash → Capture → Analyze → Fix
│ └── actions/ # Subroutines (loaded by workflows only)
│ ├── capture-logs.md
│ ├── analyze-logs.md
│ ├── build.md
│ └── flash.md
└── platforms/esp/ # Adsum IoT Coder – for ESP (roadmap)
Analyzing a UART log drop loads log-analyzer.md + capture-logs.md + sdks/ncs/SDK.md. Debugging a failed BLE connection on a two-board setup also pulls in BLE.md, device-identity.md, and the relevant board file — and nothing else. The model gets exactly what the task requires, no more.
The bigger payoff isn’t just avoiding context overflow — it’s context quality. Even when a full static bundle would technically fit, loading only the relevant modules keeps domain knowledge in the model’s effective working set rather than letting it get buried under unrelated material as the session grows. This is the “lost in the middle” failure mode the benchmark caught Claude Code hitting on L1-T2 — same model, full 200k window, lost the original symptom by debug cycle four.
Human-curated, not AI-generated
A common trend in AI tooling is letting agents author and refine their own tool-use skills. Our own research and experimentation led us in the opposite direction for high-stakes IoT debugging. Every module in iot-knowledge/ is hand-authored or hand-reviewed by senior IoT engineers. AI-generated skills can read fluently and still encode subtle misunderstandings of a protocol stack — failing in ways the agent can’t self-detect. Expert curation is the bottleneck that keeps the quality bar honest.
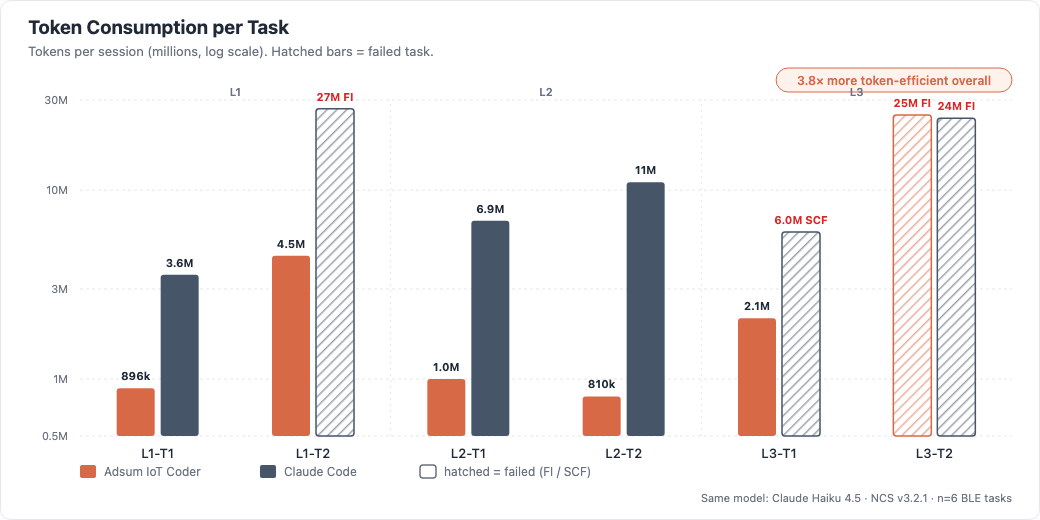
We don’t isolate “human-curated vs. AI-generated” as a single benchmark variable — our system pairs curation with dynamic loading, and we report on the combined architecture. What that architecture demonstrates: same model on both sides, 5/6 vs 3/6 tasks resolved at 3.8× lower token cost than the general-agent baseline (full results in the benchmark). As the knowledge base grows, the benchmark is how we prove we’re moving in the right direction.
Benchmark — IoT-FirmwareDebugBench v0.1
5/6 vs 3/6 tasks. 3.8× more token-efficient. Same model — Claude Haiku 4.5.
A clean architecture is only useful if it produces measurably better outcomes. Standard SWE benchmarks don’t exercise hardware-in-the-loop work, and there is no established public benchmark for AI agents on embedded IoT firmware. We adapted methodology from recent research on expert-skill-augmented LLM evaluation for embedded code generation (arXiv:2603.19583) and built one — published open source as a deliverable equal in importance to the tool itself.
IoT-FirmwareDebugBench v0.1 runs on real nRF52840 DK and nRF52832 DK boards with NCS v3.2.1 (Zephyr 4.2.99). Six BLE-focused tasks across three difficulty levels, each with a precisely injected bug, defined reproduction procedure, and known correct fix. The most important methodological choice: both agents run the same model — Claude Haiku 4.5, with reasoning mode disabled and prompt caching enabled identically. This isolates a single variable — domain architecture. If Adsum IoT Coder outperforms, it is not because it has access to a more capable model; it is because the architecture wraps the same model differently.
Difficulty levels. L1 — root cause readable directly from logs. L2 — requires inference from BLE behavior or Kconfig dependencies. L3 — requires correlating state across two devices or full session timelines.
A “flash” in the metric table below = one agent attempt: propose a fix → build → flash to the device → re-test. BC@k = “Bug Closed within k flashes.”
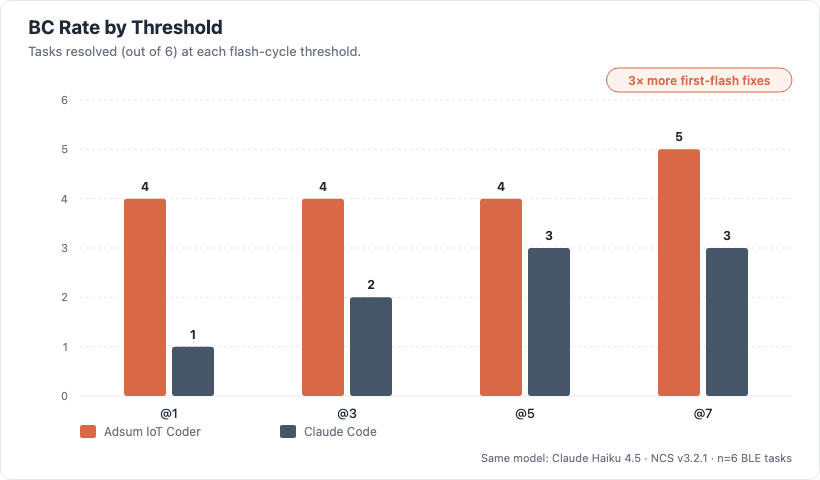
| Metric | Adsum IoT Coder | Claude Code |
|---|---|---|
| BC@1 — resolved on first flash | 4 / 6 | 1 / 6 |
| BC@7 — within seven flashes | 5 / 6 | 3 / 6 |
| L1 (visible in logs) | 2 / 2 | 1 / 2 |
| L2 (inference required) | 2 / 2 | 2 / 2 |
| L3 (cross-device) | 1 / 2 | 0 / 2 |
| Total tokens consumed | 34.3M | 78.5M |
| Tokens per resolved task | 1.86M | 7.15M |
Static Code Fix as a failure mode. Claude Code skipped log capture on two tasks and diagnosed from source code alone — what the benchmark report classifies as Static Code Fix (SCF): a methodology failure regardless of whether the resulting patch happens to compile. On L3-T1, the resulting fix was indeterminate — the root cause (bond asymmetry) is only visible through cross-device log correlation. The dynamic skill architecture eliminates this failure mode by design: log capture is a first-class step in the loaded workflow, not an optional step the agent might skip under exploration pressure.
Two other patterns worth noting: context degradation predicted failure (Claude Code burned 27M tokens on L1-T2 and lost the original symptom by the later debug cycles; Adsum IoT Coder resolved it at 148.7k peak), and the gap widens with task difficulty (parity at L2, Adsum 1/2 vs 0/2 at L3). Full per-task breakdown in the benchmark report.
The architecture and the benchmark are two halves of the same commitment: domain-specific AI tooling clean enough to extend, and measurable enough to defend. Run it yourself — that’s the conversation we want to be in.
Getting Started
Open the VS Code Extensions panel and search for Adsum IoT Coder, then click Install. Or install from the VS Code Marketplace directly.
See CHANGELOG.md for release notes.
Install it and you can start immediately — the free tier runs on a managed model, so there’s no provider screen to clear first. Add your own key whenever you want.


The home on first run (left) and after opening an nRF project (right) — it adapts to what you're working on.
Start with the 30-second demo. The home screen leads with a live demo that debugs a real BLE bug on firmware bundled with the extension — capture → analyze → fix on a genuine failure, with no board or project of your own needed. It’s the fastest way to see how the agent works before pointing it at your code.
Then the home screen adapts to your project. Open your NCS project and the agent reads what it is, then offers the right next moves as one-click actions:
- Build, flash & debug — the full loop: build your code, flash it, capture live RTT/UART logs, find the issue, and iterate (Build → Flash → Capture → Analyze → Fix) until it’s resolved or you stop it. Boards auto-detect via J-Link, with multi-device simultaneous capture and source-aware correlation.
- Add a feature — wire a new capability (a Zephyr shell, a BLE service, NVS storage…) into your actual project, not a throwaway sample.
- Test & validate — exercise your firmware with host tests and on-hardware checks.
After any task finishes, the agent suggests where to go next, so you’re never left at a blank prompt.
Requirements
| Requirement | Details |
|---|---|
| nRF Connect SDK | v3.2.1 |
| Supported SoCs | nRF52, nRF53, nRF54 |
| Supported Protocols | BLE |
| VS Code Extension | nRF Connect Extension Pack |
| Python | 3.8+ (bundled with nRF Connect extension) |
| AI Provider | Any OpenAI-compatible endpoint (cloud or local — see Tested Models) |
Free tier — start without a key
You told us the first step was too much work: wire up a provider, paste an API key, then find out if the tool helps. We cut that.
Install the extension and start debugging — no key, no account, no card. Inference runs on a managed model hosted by Adsum Networks, so you can evaluate the agent on your own firmware in the first minute. When you want unlimited usage or a specific model, drop in your own key (any OpenAI-compatible provider) and the switch is instant — the session you’re in keeps running, no restart.
| Free tier | Bring your own key | |
|---|---|---|
| API key | Not required | Required |
| Model | Managed by Adsum | Any OpenAI-compatible model |
| Good for | First run, evaluation, quick fixes | Daily driver, long debug loops, model choice |
The free tier is token-metered. When you hit the limit, the agent surfaces a one-click “add your own key” prompt and the same task picks up where it left off on your provider.
Tested Models
Try Claude Haiku 4.5 first — it’s the model we have IoT-specific benchmark evidence for. DeepSeek-V4-Pro is the cost play for long sessions where margin matters more than empirical confidence.
| Model | Best for | Notes |
|---|---|---|
| Claude Haiku 4.5 ⭐ | First try / production | Used in the IoT-FirmwareDebugBench evaluation |
| DeepSeek-V4-Pro ⭐ | Cost-sensitive long sessions | Larger context window → fewer overflow failures on long debug loops. Cheaper per million tokens than Haiku. Via OpenRouter or DeepSeek API. |
| GLM 5.1 | Worth watching | Previously our cost-sensitive recommendation; DeepSeek-V4-Pro has since outpaced it on performance, context window, and price. Still works as an OpenAI-compatible endpoint. |
Any OpenAI-compatible endpoint works, provided the model has strong tool-calling (function-calling) capabilities. Models without native tool-use support cannot execute hardware actions or debug workflows.
Configuring a provider. Open VS Code Settings → search for “Adsum IoT Coder” → set the API endpoint URL and key. Any OpenAI-compatible endpoint is accepted (OpenRouter, DeepSeek API, Anthropic via a compatible gateway, or a local Ollama / LM Studio server).
Recommended setup for Claude Haiku 4.5 — matches the benchmark configuration:
| Setting | Value |
|---|---|
| API Provider | OpenRouter (or any OpenAI-compatible endpoint) |
| Model | anthropic/claude-haiku-4.5 |
| Enable thinking | Off |
| Prompt caching (Advanced) | On |
Roadmap
The product line is Adsum IoT Coder, with each release scoped to a specific IoT chip family. “IoT” reflects the focus: communication stacks and the power-budget concerns that come with them — BLE, Wi-Fi, Thread, Matter, LTE-M — rather than generic embedded coding. “Coder” reflects the trajectory: this release ships debugging because that’s where general agents fail hardest and the value is most measurable, but the architecture is designed to cover the full IoT communication development lifecycle — design, implementation, verification, and field optimization — as new modules and skills land.
| Category | Current (shipping) | Next (roadmap) |
|---|---|---|
| Platform release | Adsum IoT Coder – for nRF | Adsum IoT Coder – for ESP |
| SoC families | nRF52, nRF53, nRF54 | nRF7x (Wi-Fi), nRF9x (cellular), ESP32x |
| Protocols | BLE | Wi-Fi, Thread, Matter, LTE-M, DECT NR+ |
| NCS versions | v3.2.x | v2.9.x LTS, v3.3+ |
| HITL tooling | RTT/UART log capture, J-Link multi-device control | BLE sniffer integration, PPK II power profiling, spectrum analysis |
| Dev-lifecycle scope | Debugging (capture → analyze → fix loop) | Power-budget review, protocol-correctness review, architectural review, low-power optimization |
| Benchmark | v0.1 (6 BLE tasks on nRF5x) | v0.2 (20+ tasks, Copilot comparison, ESP suite) |
The roadmap is shaped by what the community asks for and contributes. Open an issue, propose a benchmark task, or contribute a knowledge module.
Limitations
We publish what’s true today, not what we wish were true.
Product
- Scope. Today the tool ships for nRF52, nRF53, and nRF54 with BLE. Other Nordic families (nRF7x, nRF9x) and other vendors (ESP) are roadmap, not shipping. Other protocols (Wi-Fi, Thread, Matter, LTE-M) are roadmap, not shipping.
- Free-tier token counter. The “tokens left” chip decrements by each request’s real usage and shows 0 the moment your quota is exhausted. On a cold start it briefly shows the last-known balance until it re-syncs with the backend (a second or two); the real balance always lives in the backend and is enforced there.
- Trademarks. nRF, nRF Connect SDK, and Nordic Semiconductor are trademarks of Nordic Semiconductor ASA. This project is independently developed and not affiliated with or endorsed by Nordic Semiconductor ASA.
Benchmark
- Sample size. Six tasks is sufficient for a proof-of-concept evaluation, not statistical significance. v0.2 targets 20–30 tasks.
- SDK coverage. All benchmark tasks ran on a single NCS version (v3.2.1). Older LTS versions are roadmap items.
- Single-evaluator scoring. All benchmark sessions were run and scored by one person. Independent replication is actively welcomed.
- Comparison breadth. GitHub Copilot and OpenAI Codex evaluations are planned for v0.2; token visibility on the free tier delayed Copilot from v0.1.
- Open unsolved task. L3-T2 (HIDS security mismatch — central requests
BT_SECURITY_L3MITM, peripheral offersBT_SECURITY_L1) remains unresolved by both agents. Diagnosing it requires SMP-layer event correlation invisible from UART alone. BLE sniffer integration (roadmap) is the planned approach.
The methodology is open precisely so others can probe these limits, run independent comparisons, and contribute tasks.
Citing this work
If you reference the benchmark or this work in research, please cite:
@misc{adsumiotcoder2026,
title = {IoT-FirmwareDebugBench v0.1: A Hardware-in-the-Loop
Evaluation Suite for AI IoT Firmware Debugging Agents},
author = {Adsum Networks},
year = {2026},
url = {https://github.com/adsumnetworks/Adsum-IoT-Coder},
note = {Open source under Apache 2.0}
}
About
Adsum Networks — 8+ years building IoT solutions on Nordic and other embedded platforms. Our v1 proof of concept, nRF AI Debugger, reached 200+ installs in its first two months — enough signal to rebuild the architecture for what’s next.
We built Adsum IoT Coder because general coding agents leave IoT firmware developers without reliable AI assistance for the hardest debugging scenarios — protocol failures, power-budget violations, and runtime-only bugs that don’t show up in source review. Our belief: domain-specific AI tooling needs to be (a) built by engineers who have lived inside the failure modes, and (b) measured against open benchmarks so the value can be defended, not just claimed. Both halves of that conviction are in this release.
Contributing
We welcome new benchmark tasks, knowledge modules, and HITL tool integrations.
- Knowledge modules are Markdown files in
iot-knowledge/following the structure in Architecture. Add a new protocol, board, or workflow as its own module. - Benchmark tasks follow the format in
evals/. Each task ships its bug-injection patch, reproduction procedure, and known-correct fix.
Open an issue to discuss before larger changes, or open a PR directly for small fixes.
Privacy & Security
The extension’s runtime runs entirely on your machine. Outbound network requests go only to the AI provider you configured, carrying only the data listed below.
Sent to the model:
- Log snippets the agent has captured during the active session
- Source files and Kconfig the agent has opened in this task
- Tool-call results (build output, flash output, device responses)
Never sent:
- Files outside the active workspace
.envfiles, credentials, signing keys, board UUIDs/MAC addresses- Background workspace scans, idle file watchers, or telemetry from the agent runtime itself
BYOK (Bring Your Own Key) — you control which model and endpoint you trust. Source is fully open and auditable.
Local models work. Any OpenAI-compatible endpoint can be configured, including locally-hosted models via Ollama, LM Studio, or llama.cpp’s built-in server — useful for privacy-sensitive projects where data cannot leave the developer’s machine. A model with strong native tool-calling is required; small local models often fall short.
Telemetry. Anonymous product analytics — installs, activations, feature and free-tier usage, and execution errors, keyed to a random install ID. Never source code, file paths, chat content, or device logs. Opt out: set telemetry.telemetryLevel to off in VS Code settings.
Troubleshooting
Shell integration warning on first run — restart VS Code and open a new terminal session.
Linux notifications — if ENOENT errors appear when tasks complete: sudo apt install libnotify-bin
J-Link not detected / board not auto-detected — confirm the SEGGER J-Link drivers are installed and the board enumerates in nrfjprog --ids. Re-plug the board and reload the VS Code window.
Flash command fails — make sure no other tool (nRF Connect for Desktop, OpenOCD) holds the J-Link interface. Only one process can flash at a time.
AI provider authentication errors — verify your API key in the extension settings and that the endpoint URL matches your provider (e.g. https://openrouter.ai/api/v1 for OpenRouter).
Model refuses tool calls / returns plain text — the configured model must support native tool-calling. Models without function-calling support cannot drive hardware workflows. See Tested Models.
Still stuck? Open a Discussion — we read every one.
Acknowledgments
- Cline — The open-source AI coding agent this project builds upon.
- The authors of arXiv:2603.19583 — For their research on expert-skill-augmented LLM evaluation for embedded code generation, which inspired our benchmarking methodology.